Prior to that, I spent 5 wonderful years as an assistant professor at the University of Michigan in the EECS department. I did my PhD at MIT CSAIL,
where I was advised by William
Freeman and Antonio
Torralba, and I was a postdoc at UC Berkeley with Alyosha Efros
and Jitendra
Malik. I was an undergrad at Cornell.
|
|
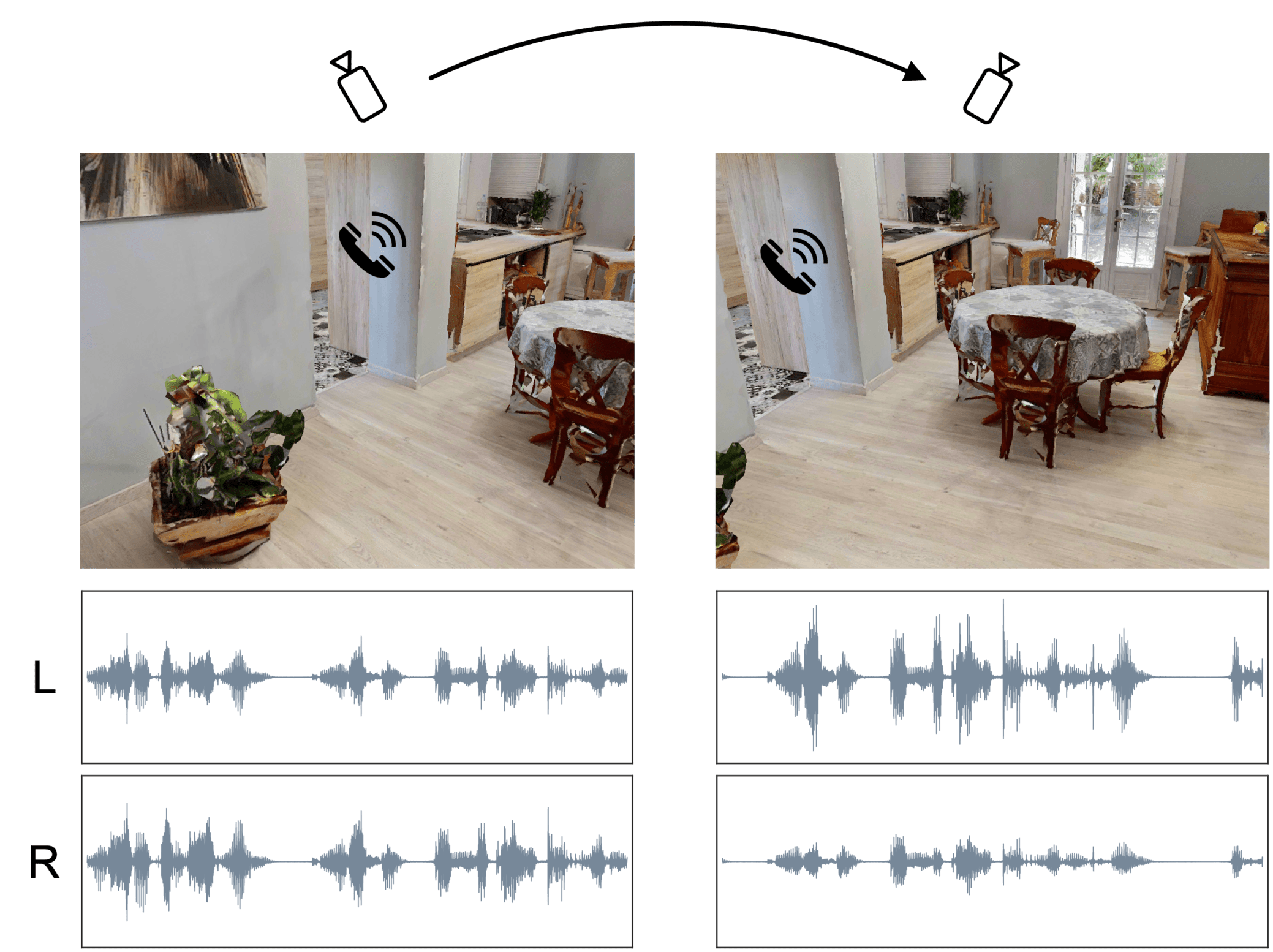
| New York Smells: A Large Multimodal Dataset for Olfaction |
| Ege Ozguroglu, Junbang Liang, Ruoshi Liu, Mia Chiquier, Michael DeTienne, Wesley Wei Qian, Alexandra Horowitz, Andrew Owens, Carl Vondrick |
| arXiv 2025 |
| project page · paper · bibtex |
|
@article{ozguroglu2025new,
title={New York Smells: A Large Multimodal Dataset for Olfaction},
author={Ozguroglu, Ege and Liang, Junbang and Liu, Ruoshi and Chiquier, Mia and DeTienne, Michael and Qian, Wesley Wei and Horowitz, Alexandra and Owens, Andrew and Vondrick, Carl},
journal={arXiv},
year={2025},
}
A dataset of in-the-wild smell and vision.
|
|
|
|
|
|
|
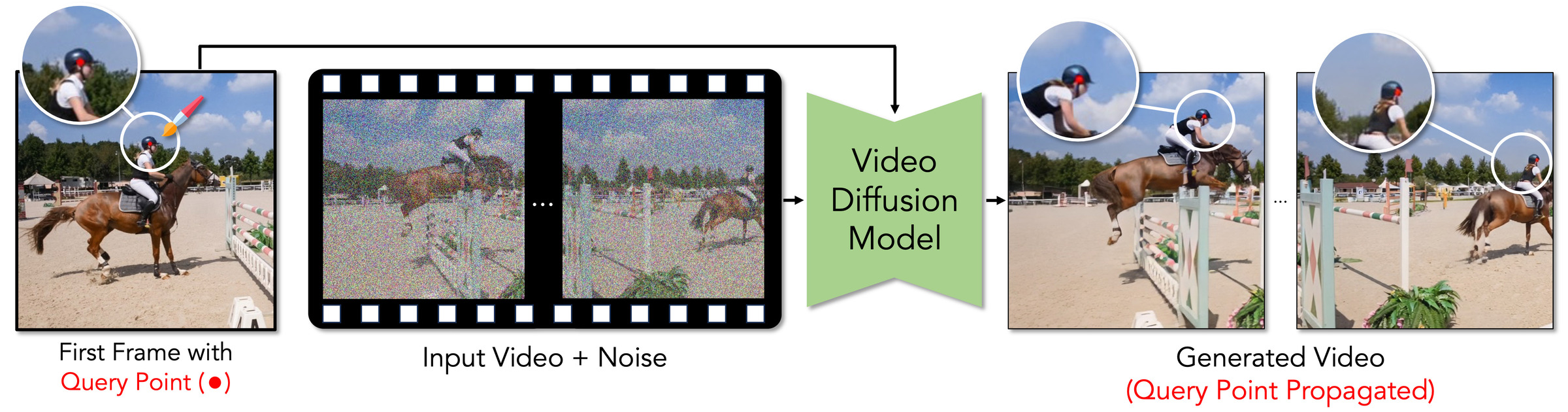
| Point Prompting: Counterfactual Tracking with Video Diffusion Models |
| Ayush Shrivastava*, Sanyam Mehta*, Daniel Geng, Andrew Owens |
| ICLR 2026 |
| project page · paper · bibtex |
|
@article{shrivastava2026point,
title={Point Prompting: Counterfactual Tracking with Video Diffusion Models},
author={Shrivastava, Ayush and Mehta, Sanyam and Geng, Daniel and Owens, Andrew},
journal={International Conference on Learning Representations (ICLR)},
year={2026},
}
Use simple prompts to convert video diffusion models into point trackers.
|
|
|
|
|
|
|
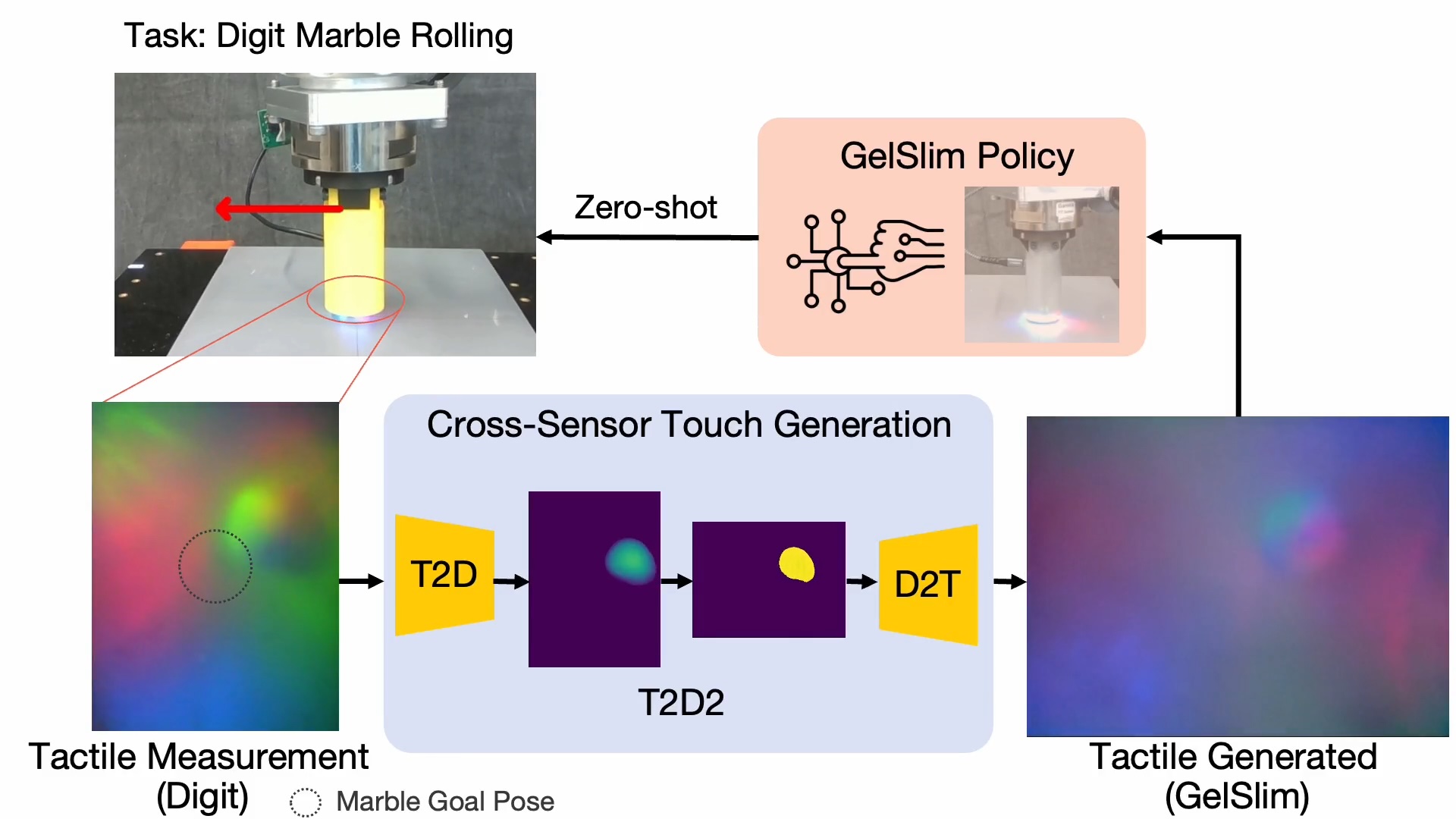
| Cross-Sensor Touch Generation |
| Samanta Rodriguez*, Yiming Dou*, Miquel Oller, Andrew Owens, Nima Fazeli |
| CoRL 2025 |
| project page · paper · bibtex |
|
@article{rodriguez2025crosssensor,
title={Cross-Sensor Touch Generation},
author={Rodriguez, Samanta and Dou, Yiming and Oller, Miquel and Owens, Andrew and Fazeli, Nima},
journal={Conference on Robot Learning (CoRL)},
year={2025},
}
We learn to translate touch signals acquired from one vision-based touch sensor to another. This allows us to transfer object manipulation algorithms between sensors.
|
|
|
|
|
|
|
| GPS as a Control Signal for Image Generation |
| Chao Feng, Ziyang Chen, Aleksander Holynski, Alexei A. Efros, Andrew Owens |
| CVPR 2025 |
| project page · paper · bibtex |
|
@article{feng2025gps,
title={GPS as a Control Signal for Image Generation},
author={Feng, Chao and Chen, Ziyang and Holynski, Aleksander and Efros, Alexei A and Owens, Andrew},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2025},
}
We generate images conditioned on GPS.
|
|
|
|
|
|
|
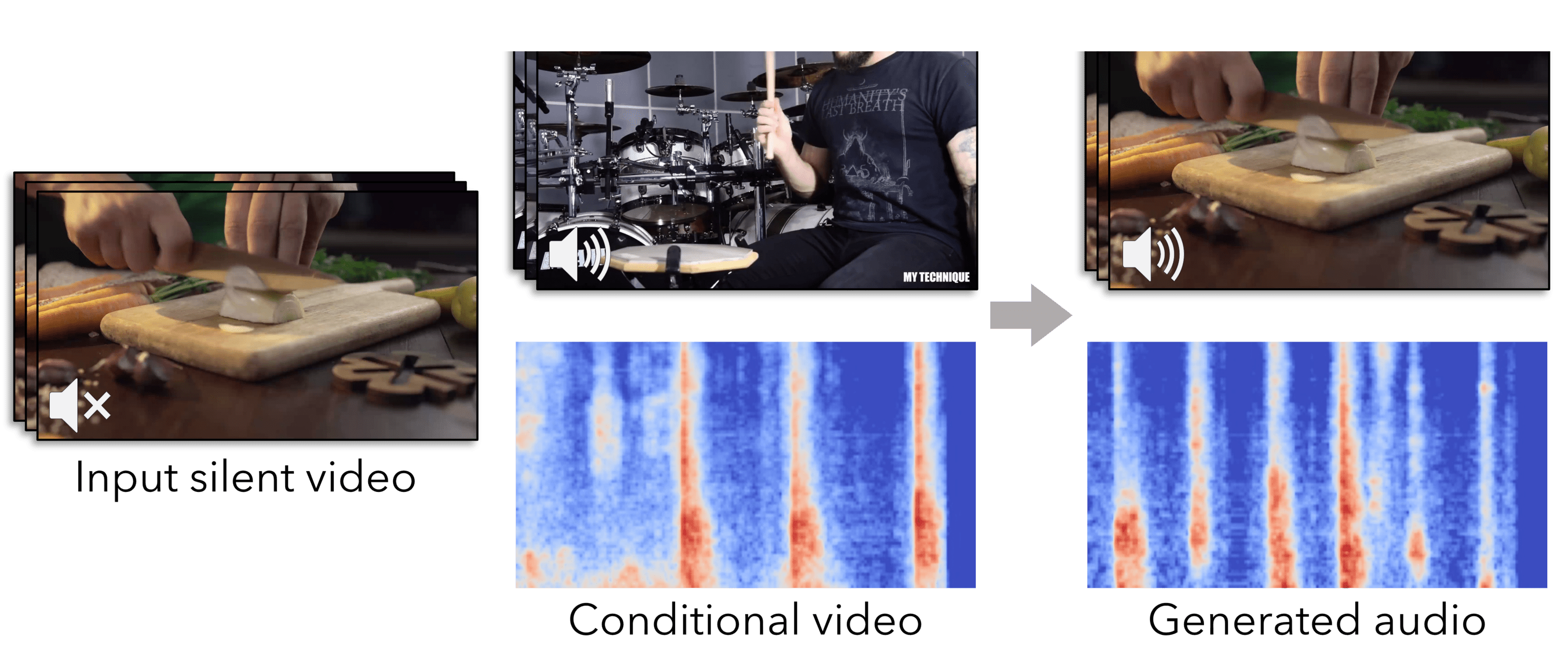
| Video-Guided Foley Sound Generation with Multimodal Controls |
| Ziyang Chen, Prem Seetharaman, Bryan Russell, Oriol Nieto, David Bourgin, Andrew Owens, Justin Salamon |
| CVPR 2025 |
| project page · paper · bibtex |
|
@article{chen2025videoguided,
title={Video-Guided Foley Sound Generation with Multimodal Controls},
author={Chen, Ziyang and Seetharaman, Prem and Russell, Bryan and Nieto, Oriol and Bourgin, David and Owens, Andrew and Salamon, Justin},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2025},
}
Generate synchronized audio for silent videos using text or audio conditioning.
|
|
|
|
|
|
|
|
|
|
| Motion Prompting: Controlling Video Generation with Motion Trajectories |
| Daniel Geng, Charles Herrmann, Junhwa Hur, Forrester Cole, Chen Sun, Oliver Wang, Tobias Pfaff, Tatiana Lopez-Guevara, Carl Doersch, Yusuf Aytar, Michael Rubinstein, Andrew Owens, Deqing Sun |
| CVPR 2025 |
| project page · paper · bibtex |
|
@article{geng2025motion,
title={Motion Prompting: Controlling Video Generation with Motion Trajectories},
author={Geng, Daniel and Herrmann, Charles and Hur, Junhwa and Cole, Forrester and Sun, Chen and Wang, Oliver and Pfaff, Tobias and Lopez-Guevara, Tatiana and Doersch, Carl and Aytar, Yusuf and Rubinstein, Michael and Owens, Andrew and Sun, Deqing},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2025},
}
Control video generators using point tracks.
|
|
|
|
|
|
|
| Hearing Hands: Generating Sounds from Physical Interactions in 3D Scenes |
| Yiming Dou, Wonseok Oh, Yuqing Luo, Antonio Loquercio, Andrew Owens |
| CVPR 2025 |
| bibtex |
|
@article{dou2025hearing,
title={Hearing Hands: Generating Sounds from Physical Interactions in 3D Scenes},
author={Dou, Yiming and Oh, Wonseok and Luo, Yuqing and Loquercio, Antonio and Owens, Andrew},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2025},
}
Predict what sound a hand motion would make in a 3D scene.
|
|
|
|
|
|
|
|
|
|
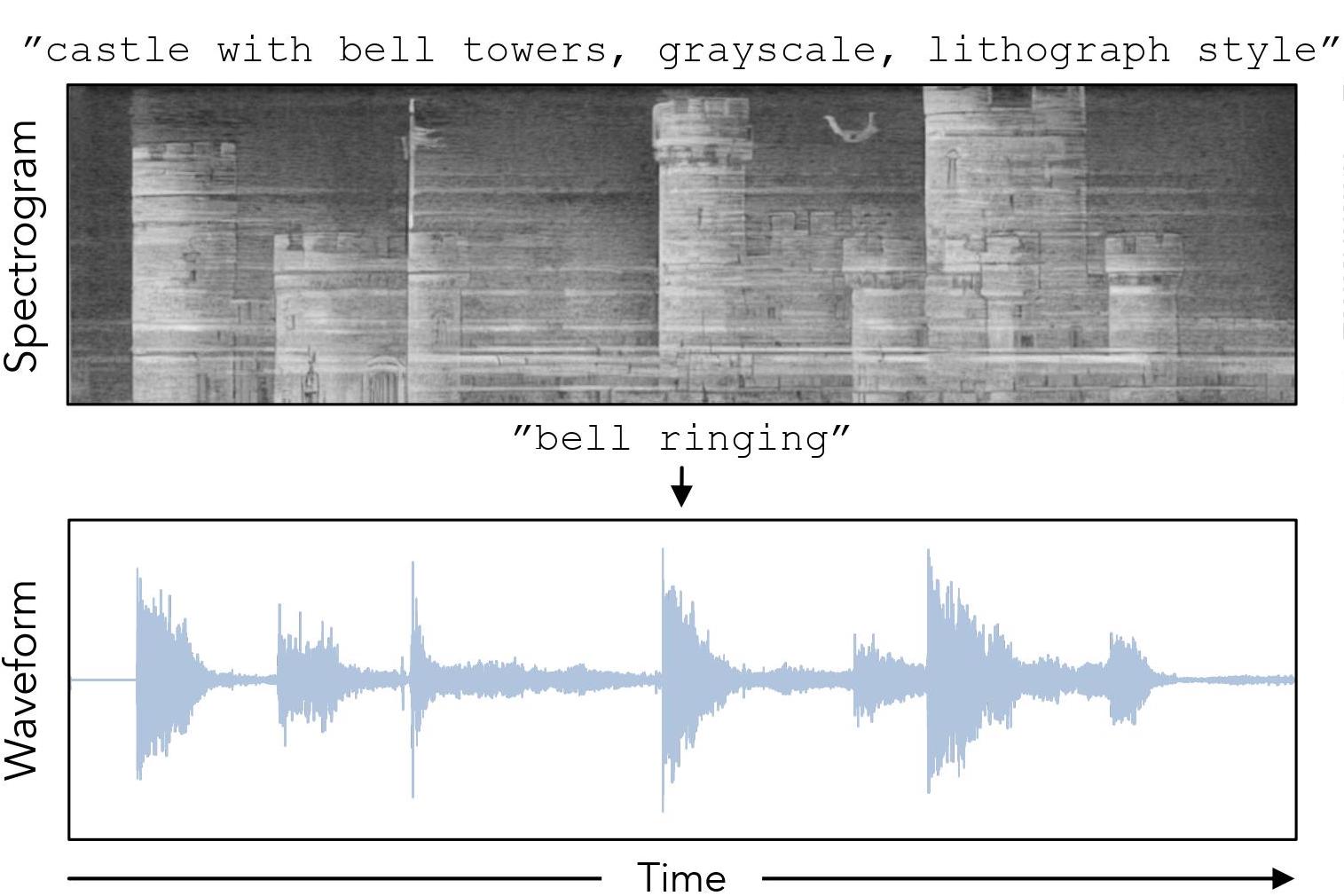
| Images that Sound: Composing Images and Sounds on a Single Canvas |
| Ziyang Chen, Daniel Geng, Andrew Owens |
| NeurIPS 2024 |
| project page · paper · bibtex |
|
@article{chen2024images,
title={Images that Sound: Composing Images and Sounds on a Single Canvas},
author={Chen, Ziyang and Geng, Daniel and Owens, Andrew},
journal={Neural Information Processing Systems (NeurIPS)},
year={2024},
}
We generate spectrograms that look like natural images by composing together the score functions of audio and visual diffusion networks.
|
|
|
|
|
|
|
| Factorized Diffusion: Perceptual Illusions by Noise Decomposition |
| Daniel Geng*, Inbum Park*, Andrew Owens |
| ECCV 2024 |
| project page · paper · bibtex |
|
@article{geng2024factorized,
title={Factorized Diffusion: Perceptual Illusions by Noise Decomposition},
author={Geng, Daniel and Park, Inbum and Owens, Andrew},
journal={European Conference on Computer Vision (ECCV)},
year={2024},
}
Make hybrid images (and other illusions) by linearly filtering the noise during diffusion generation.
|
|
|
|
|
|
|
|
|
|
| Self-Supervised Audio-Visual Soundscape Stylization |
| Tingle Li, Renhao Wang, Po-Yao Huang, Andrew Owens, Gopala Krishna Anumanchipalli |
| ECCV 2024 |
| project page · paper · bibtex |
|
@article{li2024selfsupervised,
title={Self-Supervised Audio-Visual Soundscape Stylization},
author={Li, Tingle and Wang, Renhao and Huang, Po-Yao and Owens, Andrew and Anumanchipalli, Gopala Krishna},
journal={European Conference on Computer Vision (ECCV)},
year={2024},
}
Restyle a sound to fit with another scene, using an audio-visual conditional example taken from that scene.
|
|
|
|
|
|
|
| Tactile-Augmented Radiance Fields |
| Yiming Dou, Fengyu Yang, Yi Liu, Antonio Loquercio, Andrew Owens |
| CVPR 2024 |
| project page · paper · code · bibtex |
|
@article{dou2024tactileaugmented,
title={Tactile-Augmented Radiance Fields},
author={Dou, Yiming and Yang, Fengyu and Liu, Yi and Loquercio, Antonio and Owens, Andrew},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2024},
}
We capture visual-tactile representations of real-world 3D scenes. This representation can estimate the tactile signals for a given 3D position within the scene.
|
|
|
|
|
|
|
| Visual Anagrams: Generating Multi-View Optical Illusions with Diffusion Models |
| Daniel Geng, Inbum Park, Andrew Owens |
| CVPR 2024 (Oral) |
| project page · paper · bibtex |
|
@article{geng2024visual,
title={Visual Anagrams: Generating Multi-View Optical Illusions with Diffusion Models},
author={Geng, Daniel and Park, Inbum and Owens, Andrew},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2024},
}
We generate multi-view optical illusions: images that change their appearance under a transformation, such as a flip or a rotation.
|
|
|
|
|
|
|
| Real Acoustic Fields: An Audio-Visual Room Acoustics Dataset and Benchmark |
| Ziyang Chen, Israel D. Gebru, Christian Richardt, Anurag Kumar, William Laney, Andrew Owens, Alexander Richard |
| CVPR 2024 (Highlight) |
| project page · paper · bibtex |
|
@article{chen2024real,
title={Real Acoustic Fields: An Audio-Visual Room Acoustics Dataset and Benchmark},
author={Chen, Ziyang and Gebru, Israel D and Richardt, Christian and Kumar, Anurag and Laney, William and Owens, Andrew and Richard, Alexander},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2024},
}
A benchmark for real-world audio-visual room acoustics, containing NeRFs with densely sampled audio recordings.
|
|
|
|
|
|
|
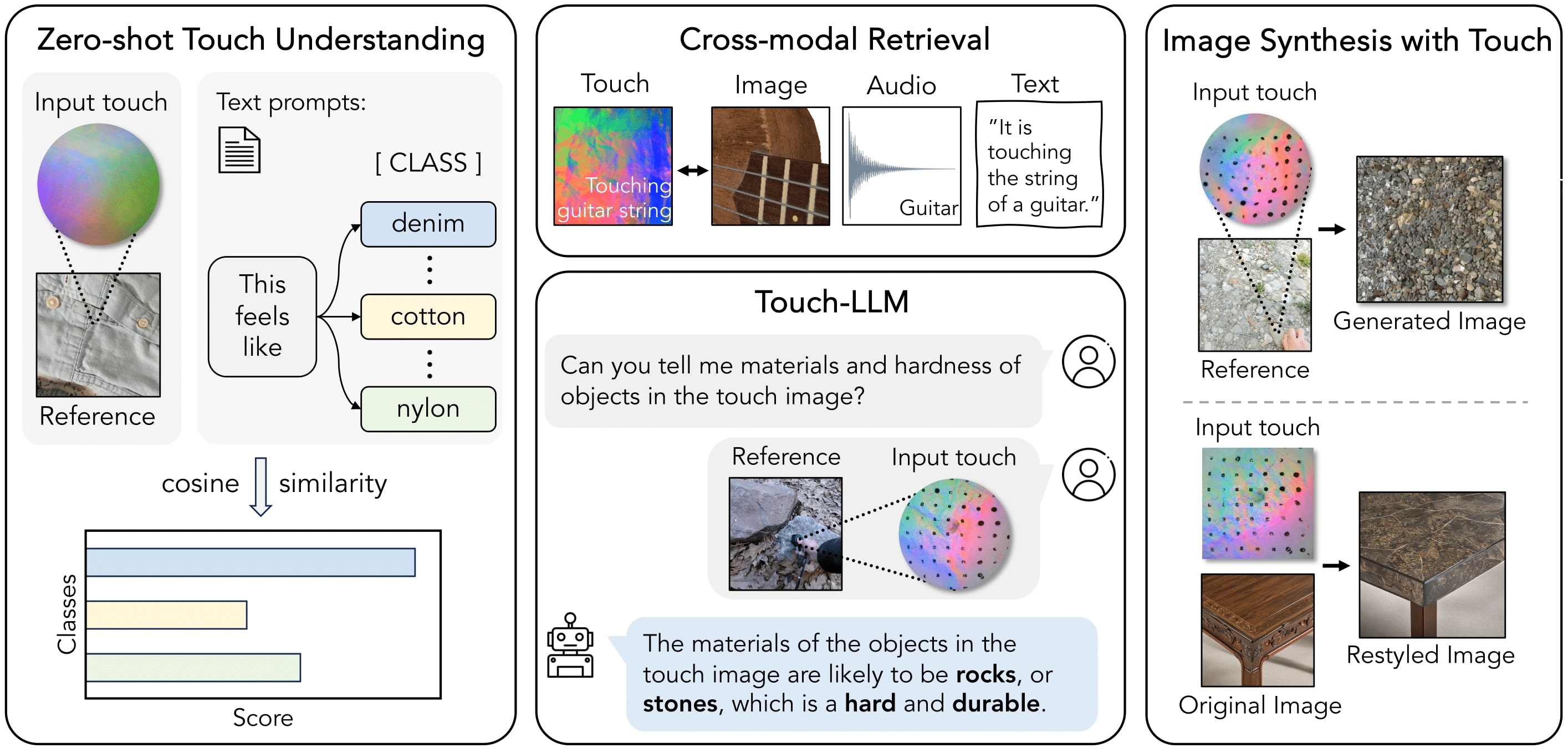
| Binding Touch to Everything: Learning Unified Multimodal Tactile Representations |
| Fengyu Yang*, Chao Feng*, Ziyang Chen*, Hyoungseob Park, Daniel Wang, Yiming Dou, Ziyao Zeng, Xien Chen, Rit Gangopadhyay, Andrew Owens, Alex Wong |
| CVPR 2024 |
| project page · paper · bibtex |
|
@article{yang2024binding,
title={Binding Touch to Everything: Learning Unified Multimodal Tactile Representations},
author={Yang, Fengyu and Feng, Chao and Chen, Ziyang and Park, Hyoungseob and Wang, Daniel and Dou, Yiming and Zeng, Ziyao and Chen, Xien and Gangopadhyay, Rit and Owens, Andrew and Wong, Alex},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2024},
}
Link the signal recorded by vision-based touch sensors to other modalities, using correspondences between sight and touch.
|
|
|
|
|
|
|
| Efficient Vision-Language Pre-training by Cluster Masking |
| Zihao Wei*, Zixuan Pan*, Andrew Owens |
| CVPR 2024 |
| project page · paper · bibtex |
|
@article{wei2024efficient,
title={Efficient Vision-Language Pre-training by Cluster Masking},
author={Wei, Zihao and Pan, Zixuan and Owens, Andrew},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2024},
}
Drop clusters of visually-similar tokens during vision-language pretraining for efficiency and better downstream performance.
|
|
|
|
|
|
|
|
|
|
| Self-Supervised Motion Magnification by Backpropagating Through Optical Flow |
| Zhaoying Pan*, Daniel Geng*, Andrew Owens |
| NeurIPS 2023 |
| project page · paper · bibtex |
|
@article{pan2023selfsupervised,
title={Self-Supervised Motion Magnification by Backpropagating Through Optical Flow},
author={Pan, Zhaoying and Geng, Daniel and Owens, Andrew},
journal={Neural Information Processing Systems (NeurIPS)},
year={2023},
}
A simple method for magnifying tiny motions: we manipulate an input video such that its new optical flow is scaled by the desired amount.
|
|
|
|
|
|
|
| Sound Localization from Motion: Jointly Learning Sound Direction and Camera Rotation |
| Ziyang Chen, Shengyi Qian, Andrew Owens |
| ICCV 2023 |
| project page · paper · bibtex |
|
@article{chen2023sound,
title={Sound Localization from Motion: Jointly Learning Sound Direction and Camera Rotation},
author={Chen, Ziyang and Qian, Shengyi and Owens, Andrew},
journal={International Conference on Computer Vision (ICCV)},
year={2023},
}
We jointly learn to localize sound sources from audio and to estimate camera rotations from images. Our method is entirely self-supervised.
|
|
|
|
|
|
|
| Generating Visual Scenes from Touch |
| Fengyu Yang, Jiacheng Zhang, Andrew Owens |
| ICCV 2023 |
| paper · site · bibtex |
|
@article{yang2023generating,
title={Generating Visual Scenes from Touch},
author={Yang, Fengyu and Zhang, Jiacheng and Owens, Andrew},
journal={International Conference on Computer Vision (ICCV)},
year={2023},
}
We use diffusion to generate images from a touch signal (and vice versa).
|
|
|
|
|
|
|
| Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models |
| Lukas Höllein*, Ang Cao*, Andrew Owens, Justin Johnson, Matthias Nießner |
| ICCV 2023 (Oral) |
| project page · paper · code · bibtex |
|
@article{hollein2023text,
title={Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models},
author={H{\"o}llein, Lukas and Cao, Ang and Owens, Andrew and Johnson, Justin and Nie{\ss}ner, Matthias},
journal={International Conference on Computer Vision (ICCV)},
year={2023},
}
We generate meshes of full 3D rooms using text-to-image models.
|
|
|
|
|
|
|
| Eventfulness for Interactive Video Alignment |
| Jiatian Sun, Longxiulin Deng, Triantafyllos Afouras, Andrew Owens, Abe Davis |
| SIGGRAPH 2023 |
| project page · paper · bibtex |
|
@article{sun2023eventfulness,
title={Eventfulness for Interactive Video Alignment},
author={Sun, Jiatian and Deng, Longxiulin and Afouras, Triantafyllos and Owens, Andrew and Davis, Abe},
journal={Proceedings of ACM SIGGRAPH},
year={2023},
}
We learn a representation that makes it easy for users to align videos and sounds.
|
|
|
|
|
|
|
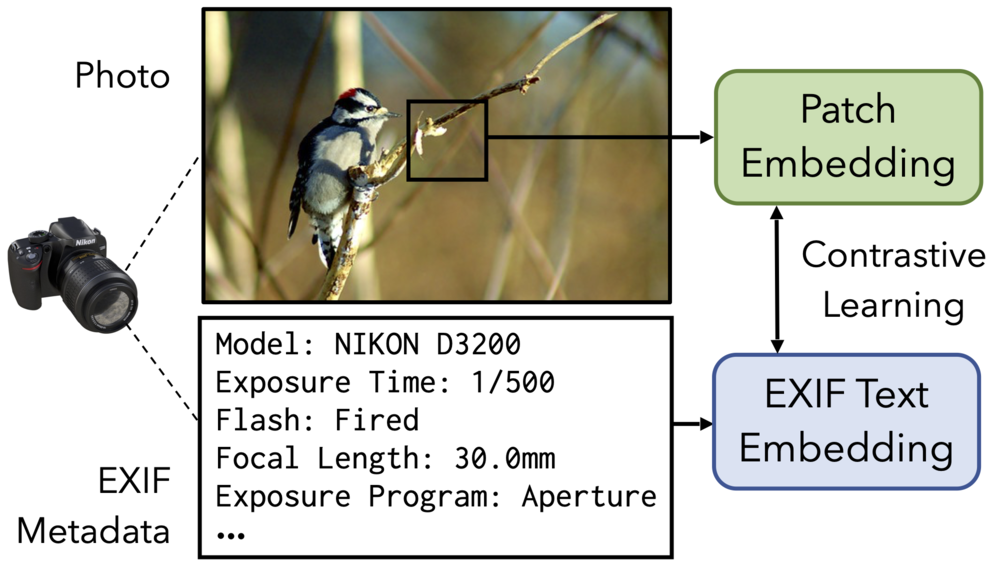
| EXIF as Language: Learning Cross-Modal Associations Between Images and Camera Metadata |
| Chenhao Zheng, Ayush Shrivastava, Andrew Owens |
| CVPR 2023 (Highlight) |
| project page · paper · bibtex |
|
@article{zheng2023exif,
title={EXIF as Language: Learning Cross-Modal Associations Between Images and Camera Metadata},
author={Zheng, Chenhao and Shrivastava, Ayush and Owens, Andrew},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2023},
}
We learn visual features that capture camera properties, by training a model to learn a joint embedding between image patches and EXIF metadata. We apply it to a variety of tasks that require an understanding of camera properties, such as image forensics.
|
|
|
|
|
|
|
| GANmouflage: 3D Object Nondetection with Texture Fields |
| Rui Guo, Jasmine Collins, Oscar de Lima, Andrew Owens |
| CVPR 2023 |
| project page · paper · video · bibtex |
|
@article{guo2023ganmouflage,
title={GANmouflage: 3D Object Nondetection with Texture Fields},
author={Guo, Rui and Collins, Jasmine and de Lima, Oscar and Owens, Andrew},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2023}
}
We camouflage 3D objects using GANs and texture fields.
|
|
|
|
|
|
|
| Self-Supervised Video Forensics by Audio-Visual Anomaly Detection |
| Chao Feng, Ziyang Chen, Andrew Owens |
| CVPR 2023 (Highlight) |
| project page · paper · bibtex |
|
@article{feng2023self,
title={Self-Supervised Video Forensics by Audio-Visual Anomaly Detection},
author={Feng, Chao and Chen, Ziyang and Owens, Andrew},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2023},
}
We detect fake videos through anomaly detection, using a model that can be trained solely from real, unlabeled data.
|
|
|
|
|
|
|
| Conditional Generation of Audio from Video via Foley Analogies |
| Yuexi Du, Ziyang Chen, Justin Salamon, Bryan Russell, Andrew Owens |
| CVPR 2023 |
| paper · project page · code · bibtex |
|
@article{du2023conditional,
title={Conditional Generation of Audio from Video via Foley Analogies},
author={Du, Yuexi and Chen, Ziyang and Salamon, Justin and Russell, Bryan and Owens, Andrew},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2023},
}
We add sound effects to silent videos, given a user-supplied video indicating the sound.
|
|
|
|
|
|
|
| Sound to Visual Scene Generation by Audio-to-Visual Latent Alignment |
| Kim Sung-Bin, Arda Senocak, Hyunwoo Ha, Andrew Owens, Tae-Hyun Oh |
| CVPR 2023 |
| project page · paper · bibtex |
|
@article{sungbin2023sound,
title={Sound to Visual Scene Generation by Audio-to-Visual Latent Alignment},
author={Sung-Bin, Kim and Senocak, Arda and Ha, Hyunwoo and Owens, Andrew and Oh, Tae-Hyun},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2023},
}
We generate images from sound.
|
|
|
|
|
|
|
| Touch and Go: Learning from Human-Collected Vision and Touch |
| Fengyu Yang*, Chenyang Ma*, Jiacheng Zhang, Jing Zhu, Wenzhen Yuan, Andrew Owens |
| NeurIPS (Datasets and Benchmarks Track) 2022 |
| paper · project page · code · bibtex |
|
@article{yang2022touch,
title={Touch and Go: Learning from Human-Collected Vision and Touch},
author={Yang, Fengyu and Ma, Chenyang and Zhang, Jiacheng and Zhu, Jing and Yuan, Wenzhen and Owens, Andrew},
journal={Neural Information Processing Systems (NeurIPS) - Datasets and Benchmarks Track},
year={2022},
}
A dataset of paired vision-and-touch data collected by humans. We apply it to: 1) restyling an image to match a tactile input, 2) self-supervised representation learning, 3) multimodal video prediction.
|
|
|
|
|
|
|
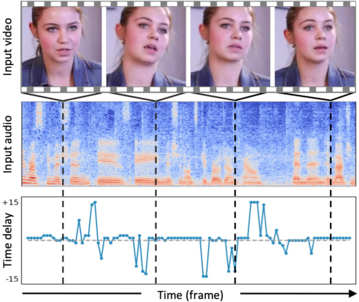
| Sound Localization by Self-Supervised Time Delay Estimation |
| Ziyang Chen, David F. Fouhey, Andrew Owens |
| ECCV 2022 |
| project page · paper · code · bibtex |
|
@article{chen2022sound,
title={Sound Localization by Self-Supervised Time Delay Estimation},
author={Chen, Ziyang and Fouhey, David F and Owens, Andrew},
journal={European Conference on Computer Vision (ECCV)},
year={2022},
}
We learn through self-supervision to find correspondences between stereo channels, which can be used to estimate a sound source's time delay.
|
|
|
|
|
|
|
| Learning Visual Styles from Audio-Visual Associations |
| Tingle Li, Yichen Liu, Andrew Owens, Hang Zhao |
| ECCV 2022 |
| project page · paper · bibtex |
|
@article{li2022learning,
title={Learning Visual Styles from Audio-Visual Associations},
author={Li, Tingle and Liu, Yichen and Owens, Andrew and Zhao, Hang},
journal={European Conference on Computer Vision (ECCV)},
year={2022},
}
We learn from unlabeled data to manipulate the style of an image using sound.
|
|
|
|
|
|
|
| Learning Pixel Trajectories with Multiscale Contrastive Random Walks |
| Zhangxing Bian, Allan Jabri, Alexei A. Efros, Andrew Owens |
| CVPR 2022 |
| project page · paper · code · bibtex |
|
@article{bian2022learning,
title={Learning Pixel Trajectories with Multiscale Contrastive Random Walks},
author={Bian, Zhangxing and Jabri, Allan and Efros, Alexei A. and Owens, Andrew},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
We learn to densely track pixels in a video using multiscale contrastive random walks, leading to a unified model that can be applied to both optical flow and long-range tracking.
|
|
|
|
|
|
|
| Comparing Correspondences: Video Prediction with Correspondence-wise Losses |
| Daniel Geng, Max Hamilton, Andrew Owens |
| CVPR 2022 |
| project page · paper · code · bibtex |
|
@article{geng2022comparing,
title={Comparing Correspondences: Video Prediction with Correspondence-wise Losses},
author={Geng, Daniel and Hamilton, Max and Owens, Andrew},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
A simple "loss extension" that makes models more robust to small positional errors: match the predicted and ground truth images using optical flow, then measure the similarity of corresponding pairs of pixels.
|
|
|
|
|
|
|
|
|
|
| Strumming to the Beat: Audio-Conditioned Contrastive Video Textures |
| Medhini Narasimhan, Shiry Ginosar, Andrew Owens, Alexei A. Efros, Trevor Darrell |
| WACV 2022 (Oral) |
| Best Paper Honorable Mention |
| project page · paper · bibtex |
|
@inproceedings{narasimhan2022strumming,
title={Strumming to the Beat: Audio-Conditioned Contrastive Video Textures},
author={Narasimhan, Medhini and Ginosar, Shiry and Owens, Andrew and Efros, Alexei A and Darrell, Trevor},
journal={Winter Conference on Applications of Computer Vision (WACV)},
year={2022}
}
We learn a representation for creating video textures using contrastive learning.
|
|
|
|
|
|
|
|
|
|
| Planar Surface Reconstruction from Sparse Views |
| Linyi Jin, Shengyi Qian, Andrew Owens, David F. Fouhey |
| ICCV 2021 (Oral) |
| project page · paper · video · code · bibtex |
|
@article{jin2021planar,
title={Planar Surface Reconstruction from Sparse Views},
author={Jin, Linyi and Qian, Shengyi and Owens, Andrew and Fouhey, David F},
journal={International Conference on Computer Vision (ICCV)},
year={2021}
}
We create a planar reconstruction of a scene from two very distant camera viewpoints.
|
|
|
|
|
|
|
| Space-Time Correspondence as a Contrastive Random Walk |
| Allan Jabri, Andrew Owens, Alexei A. Efros |
| NeurIPS 2020 (Oral) |
| project page · paper · code · bibtex |
|
@article{jabri2020spacetime,
title={Space-Time Correspondence as a Contrastive Random Walk},
author={Jabri, Allan and Owens, Andrew and Efros, Alexei A},
journal={Neural Information Processing Systems (NeurIPS)},
year={2020}
}
A simple, self-supervised method for video representation learning. Train a random walker to traverse a graph derived from a video. Learn an affinity function that makes it return to the place it started.
|
|
|
|
|
|
|
| Self-Supervised Learning Of Audio-Visual Objects From Video |
| Triantafyllos Afouras, Andrew Owens, Joon Son Chung, Andrew Zisserman |
| ECCV 2020 |
| project page · paper · code · bibtex |
|
@article{afouras2020selfsupervised,
title={Self-supervised learning of audio-visual objects from video},
author={Afouras, Triantafyllos and Owens, Andrew and Chung, Joon Son and Zisserman, Andrew},
journal={European Conference on Computer Vision (ECCV)},
year={2020}
}
We learn from unlabeled video to represent a video as a set of discrete audio-visual objects. These can be used as drop-in replacements for face detectors in speech tasks, including 1) multi-speaker source separation, 2) active speaker detection, 3) correcting misaligned audio and visual streams, and 4) speaker localization.
|
|
|
|
|
|
|
| CNN-generated images are surprisingly easy to spot... for now |
| Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, Alexei A. Efros |
| CVPR 2020 (Oral) |
| project page · paper · code · bibtex |
|
@article{wang2019cnn,
title={CNN-generated images are surprisingly easy to spot... for now},
author={Wang, Sheng-Yu and Wang, Oliver and Zhang, Richard and Owens, Andrew and Efros, Alexei A},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2020}
}
Forensics classifiers trained to spot one type of CNN-generated image generalize surprisingly well to images made by other networks, too.
|
|
|
|
|
|
|
| Detecting Photoshopped Faces by Scripting Photoshop |
| Sheng-Yu Wang, Oliver Wang, Andrew Owens, Richard Zhang, Alexei A. Efros |
| ICCV 2019 |
| project page · paper · video · code · bibtex |
|
@article{wang2019detecting,
title={Detecting Photoshopped Faces by Scripting Photoshop},
author={Wang, Sheng-Yu and Wang, Oliver and Owens, Andrew and Zhang, Richard and Efros, Alexei A},
journal={International Conference on Computer Vision (ICCV)},
year={2019},
}
We detect manipulated face photos, using only training data that was automatically generated by scripting Photoshop.
|
|
|
|
|
|
|
| Learning Individual Styles of Conversational Gesture |
| Shiry Ginosar*, Amir Bar*, Gefen Kohavi, Caroline Chan, Andrew Owens, Jitendra Malik |
| CVPR 2019 |
| project page · paper · video · bibtex |
|
@article{ginosar2019learning,
title={Learning Individual Styles of Conversational Gesture},
author={Ginosar, Shiry and Bar, Amir and Kohavi, Gefen and Chan, Caroline and Owens, Andrew and Malik, Jitendra},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2019}
}
We predict a speaker's arm/hand gestures from audio.
|
|
|
|
|
|
|
| Audio-Visual Scene Analysis with Self-Supervised Multisensory Features |
| Andrew Owens, Alexei A. Efros |
| ECCV 2018 (Oral) |
| paper · project page · video · talk · slides (key, ppt) · code · bibtex |
|
@article{owens2018audio,
title={Audio-visual Scene Analysis with Self-Supervised Multisensory Features},
author={Owens, Andrew and Efros, Alexei A},
journal={European Conference on Computer Vision (ECCV)},
year={2018}
}
We use self-supervision to learn a multisensory representation that fuses the audio and visual streams of a
video. We apply it to: 1) sound-source localization,
2) action recognition, 3) on/off-screen audio source
separation.
|
|
|
|
|
|
|
| Fighting Fake News: Image Splice Detection via Learned Self-Consistency |
| Minyoung Huh*, Andrew Liu*, Andrew Owens, Alexei A. Efros |
| ECCV 2018 |
| paper · project page · video · code · bibtex |
|
@article{huh2018fighting,
title={Fighting Fake News: Image Splice Detection via Learned Self-Consistency},
author={Huh, Minyoung and Liu, Andrew and Owens, Andrew and Efros, Alexei A},
journal={European Conference on Computer Vision (ECCV)},
year={2018}
}
We detect images that are not "self-consistent", using an anomaly detection model that was trained only on real images.
|
|
|
|
|
|
|
| More Than a Feeling: Learning to Grasp and Regrasp using Vision and Touch |
| Roberto Calandra, Andrew Owens, Dinesh Jayaraman, Justin Lin, Wenzhen Yuan, Jitendra Malik, Edward H. Adelson, Sergey Levine |
| RA-L 2018 |
| RA-L 2018 Best Paper Award Finalist |
| paper · video · project page · bibtex |
|
@article{calandra2018more,
title={More Than a Feeling: Learning to Grasp and Regrasp using Vision and Touch},
author={Calandra, Roberto and Owens, Andrew and Jayaraman, Dinesh and Lin, Justin and Yuan, Wenzhen and Malik, Jitendra and Adelson, Edward H and Levine, Sergey},
journal={Robotics and Automation Letters (RA-L)},
year={2018}
}
We train a robot to adjust its grasp, using both vision and touch sensing.
|
|
|
|
|
|
|
| MoSculp: Interactive Visualization of Shape and Time |
| Xiuming Zhang, Tali Dekel, Tianfan Xue, Andrew Owens, Qiurui He, Jiajun Wu, Stefanie Mueller, William T. Freeman |
| UIST 2018 |
| paper · project page · bibtex |
|
@article{zhang2018mosculp,
title={MoSculp: Interactive Visualization of Shape and Time},
author={Zhang, Xiuming and Dekel, Tali and Xue, Tianfan and Owens, Andrew and Wu, Jiajun and Mueller Stefanie and Freeman, William T.},
journal={User Interface Software and Technology (UIST)},
year={2018}
}
We summarize complex motions using a representation called a motion sculpture.
|
|
|
|
|
|
|
| The Feeling of Success: Does Touch Sensing Help Predict Grasp Outcomes? |
| Roberto Calandra, Andrew Owens, Manu Upadhyaya, Wenzhen Yuan, Justin Lin, Edward H. Adelson, Sergey Levine |
| CoRL 2017 |
| paper · project page · bibtex |
|
@article{calandra2017feeling,
title={The feeling of success: Does touch sensing help predict grasp outcomes?},
author={Calandra, Roberto and Owens, Andrew and Upadhyaya, Manu and Yuan, Wenzhen and Lin, Justin and Adelson, Edward H and Levine, Sergey},
journal={Conference on Robot Learning (CoRL)},
year={2017}
}
Touch sensing makes it easier to tell whether a grasp will succeed.
|
|
|
|
|
|
|
| Shape-independent Hardness Estimation Using Deep Learning and a GelSight Tactile Sensor |
| Wenzhen Yuan, Chenzhuo Zhu, Andrew Owens, Mandayam Srinivasan, Edward H. Adelson |
| ICRA 2017 |
| paper · video · bibtex |
|
@inproceedings{yuan2017shape,
title={Shape-independent Hardness Estimation Using Deep Learning and a GelSight Tactile Sensor},
author={Yuan, Wenzhen and Zhu, Chenzhuo and Owens, Andrew and Srinivasan, Mandayam A and Adelson, Edward H},
journal={International Conference on Robotics and Automation (ICRA)},
year={2017},
}
We can estimate the hardness of an object by analyzing the way that it deforms a touch sensor.
|
|
|
|
|
|
|
| Ambient Sound Provides Supervision for Visual Learning |
| Andrew Owens, Jiajun Wu, Josh McDermott, William T. Freeman, Antonio Torralba |
| ECCV 2016 (Oral) |
| paper · journal paper (2018) · project page · models · bibtex |
|
@inproceedings{owens2018ambient,
title={Learning Sight From Sound: Ambient Sound Provides Supervision for Visual Learning},
author={Owens, Andrew and Wu, Jiajun and McDermott, Josh H and Freeman, William T and Torralba, Antonio},
journal={International Journal of Computer Vision (IJCV)},
year={2018},
}
@inproceedings{owens2016ambient,
title={Ambient Sound Provides Supervision for Visual Learning},
author={Owens, Andrew and Wu, Jiajun and McDermott, Josh H and Freeman, William T and Torralba, Antonio},
journal={European Conference on Computer Vision (ECCV)},
year={2016},
}
When we train a neural network to predict sound from sight, it learns to recognize objects and scenes — without using any labeled training data.
|
|
|
|
|
|
|
| Visually Indicated Sounds |
| Andrew Owens, Phillip Isola, Josh McDermott, Antonio Torralba, Edward H. Adelson, William T. Freeman |
| CVPR 2016 (Oral) |
| paper · project page · video · bibtex |
|
@inproceedings{owens2016visually,
title={Visually indicated sounds},
author={Owens, Andrew and Isola, Phillip and McDermott, Josh and Torralba, Antonio and Adelson, Edward H and Freeman, William T},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2016}
}
What sound does an object make when you hit it with a drumstick? We use sound as a supervisory signal for learning about materials and actions.
|
|
|
|
|
|
|
| Camouflaging an Object from Many Viewpoints |
| Andrew Owens, Connelly Barnes, Alex Flint, Hanumant Singh, William T. Freeman |
| CVPR 2014 (Oral) |
| paper · project page · video · code · bibtex |
|
@inproceedings{owens2014camouflaging,
title={Camouflaging an object from many viewpoints},
author={Owens, Andrew and Barnes, Connelly and Flint, Alex and Singh, Hanumant and Freeman, William},
journal={Computer Vision and Pattern Recognition (CVPR)},
year={2014}
}
We texture a 3D object so that it is hard to see, no matter where it is viewed from.
|
|
|
|
|
|
|
| Shape Anchors for Data-Driven Multi-view Reconstruction |
| Andrew Owens, Jianxiong Xiao, Antonio Torralba, William T. Freeman |
| ICCV 2013 |
| paper · project page · bibtex |
|
@inproceedings{owens2013shape,
title={Shape anchors for data-driven multi-view reconstruction},
author={Owens, Andrew and Xiao, Jianxiong and Torralba, Antonio and Freeman, William},
journal={International Conference on Computer Vision (ICCV)},
year={2013}
}
Some image regions are highly informative about 3D shape. We use this idea to make a multi-view
reconstruction system that exploits single-image depth cues.
|
|
|
|
|
|
|
|
|
|
| Discrete-Continuous Optimization for Large-Scale Structure from Motion |
| David Crandall, Andrew Owens, Noah Snavely, Dan Huttenlocher |
| CVPR 2011 (Oral) |
| CVPR Best Paper Award Honorable Mention |
| paper · journal paper (2013) · project page · video · bibtex |
|
@article{crandall2013pami,
author = {David Crandall and Andrew Owens and Noah Snavely and Daniel Huttenlocher},
title = {{SfM with MRFs}: Discrete-Continuous Optimization for Large-Scale Structure from Motion},
journal = {Transactions on Pattern Analysis and Machine Intelligence (PAMI)},
year = {2013},
}
@inproceedings{crandall2011cvpr,
author = {David Crandall and Andrew Owens and Noah Snavely and Daniel Huttenlocher},
title = {Discrete-Continuous Optimization for Large-scale Structure from Motion},
journal = {Computer Vision and Pattern Recognition (CVPR)},
year = {2011}
}
Discrete Markov random fields can solve structure-from-motion problems, while incorporating extra information such as GPS and vanishing lines.
|
|
|
|
|